L'estensione del Web Semantico
Questo documento è la traduzione del documento The Semantic Web In Breadth di Aaron Swartz. Il documento originale è su http://logicerror.com/semanticWeb-long.
Ringrazio Aaron Swartz per aver concesso l'autorizzazione alla traduzione.
Traduzione di Pasquale Popolizio.
Nota: Questo documento parla delle varie parti del Web Semantico e delle loro complementarietà. Per un documento ad un livello più avanzato dai un'occhiata a The Semantic Web (Put Simply) di Sandro Hawke. Inoltre, se sei un Web developer che è interessato alla costruzione di siti Web Semantici o Servizi di Web Semantico, dai un'occhiata a The Semantic Web (for Web Developers).
Identificatori: Uniform Resource Identifier (URI)
Se voglio discutere di qualcosa, prima devo identificarlo. Come conoscere la cosa a cui ci si riferisce? Potrei farlo in modo indiretto: "la stella del Nord." "lo strano uomo nel negozio" "Quelle caramelle che Bob mangia sempre". Potrei anche scegliere di essere più diretto: "la stella Polare", "Jonathan Roberts" "Mega Warheads".
Per identificare cose sul Web, noi utilizziamo anche gli identificatori. Poiché usiamo un sistema uniforme di identificatori, e poiché ogni cosa identificata viene considerata una "risorsa", chiamiamo questi identificatori "Identificatori uniformi di risorse" o URI. Possiamo dare un URI a ogni cosa, ed ogni cosa che ha un URI può dire di "essere sul Web": il libro che comprasti la settimana scorsa, la mosca che ronzava nel tuo orecchio e ogno cosa a cui puoi pensare, tutte queste cose hanno un URI.
L'URI rappresenta le fondamenta del Web. Mentre quasi ogni altra parte del Web può essere sostituita, questo non si può dire delURI: esso mantiene insieme tutto il resto del Web.
Molto probabilmente hai già familiarità con una forma di URI: l'URL o Localizzatore Uniforme di Risorse. Un URL è un indirizzo che ti permette di visitare una pagina Web, per esempio http://www.w3.org/Addressing/. Se lo scomponi, puoi vedere che un URL dice al tuo computer dove trovare una specifica risorsa (in questo caso la parte del sito Web del W3C che parla di URL e URI). Diversamente da altre forme di URI, un URL identifica e localizza. In contrasto con un "mid:" URI. Un "mid:" URI identifica un messaggio email, ma non è in grado di localizzare una copia del messaggio.
Poiché il Web è troppo largo per essere controllato da un'organizzazione, gli URI sono decentralizzati. Nessuna persona o organizzazione controlla chi li fa o come essi possono essere usati. Mentre alcuni schemi di URI (come http:) dipendono da sistemi centralizzati (come i DNS), altri schemi (come freenet:) sono completamente decentralizzati.
Questo significa che non è necessario il permesso di nessuno per creare un URI. Puoi anche creare URI per cose che non possiedi. Mentre questa flessibilità fa degli URI strumenti molto potenti, questo comporta non pochi problemi. Poiché ognuno può creare un URI, potremo inevitabilmente trovarci con vari URI che rappresentano la stessa cosa. Peggio, non c'è modo di verificare se due URI si riferiscono esattamente alla stessa risorsa. Così, non avremo mai la possibilità di dire con certezza cosa significa un URI. Ci sono dei compromessi che devono essere realizzati se vogliamo creare qualcosa di enorme come il Web Semantico.
Una pratica comune per creare URI è cominciare con una pagina Web. La pagina descrive l'oggetto che deve essere identificato e spiega che l'URL della pagina è l'URI di quell'oggetto. Per esempio, volevo creare un URI per la mia copia di "Weaving the Web" di Tim Berners-Lee. Dapprima, ho creato una pagina Web che descriveva la mia copia. Poi, ho annotato sulla pagina che l'URL per la pagina serve come URI per la mia copia del libro. Così facendo, ho associato quell'URI (http://logiceerror.com/myWeavingTheWeb) alla mia copia di "Weaving the Web". Creare un URI può essere proprio semplice.
Puoi aver notato che, in questa istanza, l'URI (http://logiceerror.com/myWeavingTheWeb) fa un doppio lavoro: rappresenta sia il libro fisico, che la pagina Web che lo descrive. Questo è un argomento di discussione, è chiamato il Problema di Identificazione del Web Semantico e rappresenta un ricorrente punto di discussione per gli addetti ai lavori del Web Semantico.
Questo è un fatto inportante da capire. Un URI non è un gruppo di direzioni che dice al tuo computer come arrivare ad uno specifico file sul Web (sebbene esso potrebbe anche farlo). Esso rappresenta un nome per una "risorsa" (una cosa). Questa risorsa può o non può essere accessibile su Internet. L'URI può o non può fornire un modo a disposizione del tuo computer di avere maggiori informazioni su quella risorsa. Si, Un URI è un tipo di URI che non fornisce un modo per avere informazioni su una risorsa, o forse ritrovare la risorsa stessa, e altri metodi sono in fase di sviluppo per fornire informazioni su URI e le risorse che essi identificano. E' anche vero che l'abilità di dire cose sugli URI rappresenta una parte importante del Web Semantico. Ma non pensare che un URI faccia cose in più rispetto a fornire un identificatore per la risorsa.
Documenti: Extensible Markup Language (XML)
L'XML è stato scritto per essere un modo semplice di inviare documenti nel Web. Esso permette ad ognuno di scrivere il proprio formato di documento e poi scrivere un documento in quel formato. Questi formati di documenti possono includere markup per migliorare il significato del contenuto del documento. Questo markup è "suscettibile di essere letto da una macchina", cioè, i programmi possono leggerlo e capirlo. Includendo nei nostri documenti il significato suscettibile di essere capito dalle macchine, rendiamo gli stessi molto più potenti.
Consideriamo un semplice esempio: se un documento contiene alcune parole che sono marcate come "enfatizzate" (con <em>), il modo con il quale queste parole vengono rese può essere adattato al contesto. Un browser Web potrebbe semplicemente mostrarle in italic, laddove un browser vocale (che legge le pagine Web) potrebbe indicare l'enfasi cambiando il tono od il volume della sua voce. Ogni programma può rispondere in maniera appropriata al significato codificato nel markup. In contrasto, se semplicemente marco le parole come "in italic", il computer non ha modo di conoscere perché quelle parole sono in italic. E' per darle enfasi o solo per un effetto visivo? Come mostra l'effetto il browser vocale?
Ecco un esempio di testo semplice:
Io ho un nuovo cane
Senza verificare come la pensa il tuo computer, questo è solo testo. Non ha un particolare significato per il computer. Ma ora consideriamo questo stesso passaggio marcato utilizzando un linguaggio di markup basato su XML (ne faremo uno per quest'esempio):
<frase>
<persona href="http://aaronsw.com/">Io</persona> ho un nuovo
<animale>cane</animale>.
</frase>
Notate che questo ha lo stesso contenuto del testo semplice, ma parti del suo contenuto sono etichettate. Ogni etichetta consiste di due "tag": un tag di apertura (per esempio <frase>) ed un tag di chiusura (per esempio </frase>). Il nome del tag ("frase") rappresenta l'etichetta per il contenuto racchiuso dai tag. Chiamiamo "elemento" questa unione di tag e contenuto. Così l'elemento frase nell'esempio precedente contiene la frase "Io ho un nuovo cane". Questo dice al computer che "Io ho un nuovo cane" è una "frase" ma, cosa ancora più inportante, non dice al computer cosa è una frase. Di più, il computer ora ha alcune informazioni sul documento, che noi possiamo utilizzare.
In modo simile, il computer ora sa che "Io" è una "persona" (chiunque essa sia) e che "cane" è un "animale".
A volte è utile fornire maggiori informazioni sul contenuto di un elemento piuttosto che fornirle solo con il nome dell'elemento. Per esempio, il computer sa che "Io" nella frase precedente rappresenta una "persona", ma non sa quale persona. Possiamo fornire questo tipo di informazione aggiungendo attributi ai nostri elementi. Un attributo ha sia un nome che un valore. Per esempio, possiamo riscrivere il nostro esempio in questo modo:
<frase>
<persona href="http://aaronsw.com/">Io</persona> ho un nuovo
<animale type="cane" href="http://aaronsw.com/miocane>cane</animale>.
</frase>
Come avrai potuto sospettare, qui sorge un problema. Ho usato le parole "frase", "persona" e "animale" nel mio linguaggio di markup. Ma queste sono parole molto comuni. Cosa succede se altri utilizzano le stesse parole nei loro linguaggi di markmarkupup? E se queste parole hanno altri significati in altri linguaggi? Come può gestire queste cose il mio computer?
Per prevenire confusione, devo in maniera unica identificare i miei elementi di markup. A cosa c'è di meglio per identificarli che un Uniform Resource Identifier? Così assegno un URI ad ognuno dei miei elementi ed attributi. Lo faccio utilizzando gli XML Namespaces. In questo modo, ognuno può creare i propri tag e mescolarli con tag fatti da altri. Un namespace è proprio un modo di identificare una parte del Web (spazio) dal quale deriviamo il significato di questi nomi. Ho creato un "namespace" per il mio linguaggio di markup creando un URI per esso. (Come abbiamo visto precedentemente, probabilmente creerò una pagina Web per descrivere il mio linguaggio di markup e userò l'URL della mia pagina Web come URI per il mio namespace.
Poiché i tag di ognuno hanno i prori URI, non dobbiamo preoccuparci dei conflitti fra nome. L'XML, naturalmente, ci permette di abbreviare e definire URI di default così da non doverli scrivere ogni volta:
<frase
xmlns="http://example.org/xml/documents/"
xmlns:c="http://animals.example.net/xmlns/"
><c:persona c:href="http://aaronsw.com/">Io</c:persona> ho un nuovo
<c:animale>cane</c:animale>.</frase>
Dichiarazioni: Resource Description Framework (RDF)
Ora affondiamo i denti nella carne del Web Semantico. E' stupendo poter creare URI e parlare di essi con le nostre pagine Web. Comunque, sarebbe meglio poter parlare di essi in un modo tale che i computer possano cominciare a processare cosa stiamo dicendo. Per esempio, una cosa è dire "Mi piace 'Weaving the Web'" su un forum online. Ma questo cosa significa per un computer?
L'RDF ci offre il modo di realizzare dichiarazioni che sono processabili dalle macchine (machine-processable). Al momento il computer non può effettivamente "capire" cosa dici, ma può comportarsi come se lo facesse. Per esempio, potrei cercare nel Web tutte le recensioni dei libri e creare una media di valutazione per ogni libro. Così, potrei portare tali informazioni sul Web. Un altro sito Web potrebbe prendere quella informazione (l'elenco delle media delle valutazioni dei libri) e creare una pagina "La top ten delle recensioni dei libri".
L'RDF è veramente semplice. Una dichiarazione RDF è qualcosa di simile ad una semplice frase eccezion fatta che tutte le parole sono degli URI. Ogni dichiarazione RDF è composta di tre parti: un soggetto, un predicato ed un oggetto. Diamo un'occhiata ad una semplice dichiarazione:
<http://aaronsw.com/> <http://love.example.org/terms/piace>
<http://www.w3.org/People/Berners-Lee/Weaving/>.
Puoi indovinare cose dice? Il primo URI è il soggetto. In questa istanza il soggetto sono io. Il secondo URI è il predicato. Esso mette in relazione il soggetto con l'oggetto. Nella istanza, il predicato è "piace". Il terzo URI è l'oggetto. Qui l'oggetto è il libro di Tim Berner-Lee "Weaving tha Web". Così la dichiarazione RDF precedente dice che a me piace "Weaving the Web".
Si può notare che le dichiazioni RDF possono dire praticamente dire ogni cosa, e che non importa chi le dice. Non esiste un sito Web ufficiale che dice ogni cosa su Weaving the Web, o su di me. Questo porta ad un importante principio dell'RDF, che afferma "ogni cosa può dire ogni cosa su ogni cosa". L'informazione viaggia sul Web, e le persone possono dire cose contraddittorie - Bob può dire che Aaron ama Weaving the Web e John può dire che Aaron lo odia. Questa è la libertà che offre il Web.
La dichiarazione precedente è fatta in N-Triples, un linguaggio che ti permette di scrivere semplici dichiarazioni RDF. Comunque, la specifica ufficiale RDF definisce una rappresentazione dell'RDF in XML, che è un pò più complicata, ma che dice la stessa cosa:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:love="http://love.example.org/terms/"
>
<rdf:Description rdf:about="http://aaronsw.com/">
<love:reallyLikes rdf:resource="http://www.w3.org/People/Berners-Lee/Weaving/" />
</rdf:Description>
</rdf:RDF>
Ora, scrivere RDF come questo non rappresenta la cosa più semplice del mondo, e non sembra che facilmente ed nel breve termine ognuno comincerà a parlare questo nuovo strano linguaggio. Così, da dove ci aspettiamo che venga tutta questa informazione in RDF? La fonte più facile sono i database.
Al mondo ci sono migliaia di database, la maggior parte contenenti interresanti informazioni machine-processable. I governi conservano dati sugli arresti nei database; le aziende conservano i dati sugli inventari in database; le agende elettroniche conservano i nomi e i numeri telefonici delle persone in un - hai indovinato! - database. Quando l'informazione viene conservata in un database, risulta facile fare ad un computer alcune domande sui dati: "Mostrami tutti quelli arrestati negli scorsi sei mesi". "Stampami un elenco di tutti gli articoli che stanno per finire nel magazzino", "Dammi i numeri di telefono delle persone con il cognome Jones".
L'RDF è idealmente pensato per pubblicare questi database sul Web. E quando li mettiamo sul Web, diamo un URI ad ogni cosa nel database, così che altre persone possono interagire. Ora, programmi intelligenti possono cominciare ad unire insieme i dati. Usando le informazioni disponibili, il computer può cominciare a collegare il Bob Jones il cui numero telefonico è nella tua agenda con il Bob Jones che è stato arrestato la scorsa settimana e il Bob Jones che ha appena ordinato 100.000 widgets. Ora possiamo fare domande tipo: "dammi il numero di telefono di quelli che hanno ordinato più di 1.000 widget e che sono stati arrestati negli scorsi sei mesi".
Schema e Ontologie: RDF Schema, DAML+OIL e WebOnt
Tutto il lavoro sui database prevede che i dati siano perfetti. Pochi (se ce ne sono) sistemi di database sono pronti per la confusione del Web. Ogni sistema che è "hard-coded" per capire certi termini, probabilmente diverrà obsoleto, o avrà poca utilità, allorquando verranno definti nuovi termini. Come per esempio se qualcuno se ne esce con un nuovo sistema che recensisce i libri con una scala da 1-10 invece di dire cose tipo "mi piace". I programmi basati su vecchi sistemi non saranno in grado di processare le nuove informazioni.
Peggio, non esiste modo per un computer o un uomo di capire cosa può significare un termine, o come dovrebbe essere usato. L'uso di tutti questi URI è senza alcuna utilità se non descriviamo cosa significano. Ecco dove entrano in gioco gli schema e le ontologie. Uno schema e un'ontologia rappresentano modi di descrivere il significato dei termini e le loro relazioni. Questa descrizione (naturalmente in RDF) aiuta i sistemi di computer ad usare i termini più facilmente e decidere come convertirli fra di loro.
Due sistemi molto vicini e correlati, RDF Schema e il DARPA Agent Markup Language with Ontology Inference Layer (DAML+OIL), sono stati sviluppati per risolvere questo problema. Per esempio, uno schema potrebbe dichiarare che:
@prefix dc: <http://purl.org/dc/elements/1.1/> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
# A creator is a type of contributor:
dc:creator rdfs:subClassOf dc:contributor .
(Qui stiamo usando Notation3, un superset di N-Triples che permette di utilizzare più abbreviazioni).
Questo dice che un creator è una subclass (type) di contributor. Come usare tutto ciò? Diciamo per esempio che hai costruito un programma per conservare i creatori ed i collaboratori di vari documenti. Il tuo programma usa questo vocabolario (dc:creator e dc:contributor) per capire le informazioni che trova. Un giorno un elevato numero di principianti di AOL comincia a creare documenti RDF. Nessuno di essi conosce dc:creator, così essi decidono di utilizzare un proprio termine ed:has Author.
# The old way:
<http://aaronsw.com/> is dc:creator of <http://logicerror.com/semanticWeb-long> .
# The new way:
<http://logicerror.com/semanticWeb-long> ed:hasAuthor <http://aaronsw.com/> .
In genere, Il tuo programma dovrebbe semplicemente ignorare queste nuove dichiarazioni, poiché non possono capirle. Comunque, un animo gentile fu abbastanza intelligente di unire le diffenze fra queste due parole, fornendo informazioni su come convertirle fra di loro:
# [X dc:creator Y] is the same as [Y ed:hasAuthor X]
dc:creator daml:inverse ed:hasAuthor .
Questo esempio dice al tuo programma che ed:hasAuthor è l'inverso di dc:creator. Ciò significa che quello che deve fare il tuo programma è invertire il soggetto e l'oggetto e cambiare ed:hasAuthor con dc:creator. Poiché il tuo programma capisce le ontologie DAML, ora può prendere questa informazione ed utilizzarla per processare tutte le dichiarazioni hasAuthor che prima non capiva.
A tutt'oggi, 3 settembre 2001, il W3C sta lanciando il Web Ontoloy (WebOnt) Working Group (che alcuni chiamano WOW-G). La missione di questo gruppo è di preparare un linguaggio di Web Ontology che va a posizionarsi sul lavoro fatto dall'RDF Schema e da DAML+OIL. Sarà interessante vedere cosa svilupperà questo gruppo.
Logica
Da questo punto in poi, tratterò parti del Web Semantico che non sono state ancora sviluppate. Diversamente dalla discussione fatta prima, qui non parlerò di sistemi specifici, ma invece di un concetto generale che potrebbe diventare (e sta diventando) parte di molti sistemi differenti.
Mentre è semplice avere sistemi che capiscono questi concetti base (subclass, inverse, etc.) potrebbe essere ancora meglio se potessimo anche definire ogni principio logico e permettere al computer di fare ragionamenti (mediante inferenza) utilizzando questi principi.
Ecco un esempio: diciamo che un'azienda decide che se qualcuno vende più di 100 dei suoi prodotti, questi diventa membro del club del Super Venditore. Un programma intelligente ora può seguire questa regola per fare una semplice deduzione: "John ha venduto 102 cose, così John è un membro del Club del Super Venditore".
Prova
Una volta che cominciamo a costruire sistemi che seguono la logica, diventa sensato utilizzarli per provare le cose. Tutte le persone al mondo potrebbero scrivere dichiarazioni. Poi la tua macchina potrebbe seguire questi "link" Semantici per costruire prove.
Esempio: i record delle vendite aziendali mostrano che Jane ha venduto 55 cruscotti e 66 rotelle. Il sistema di inventariato ci dice che cruscotti e rotelle sono entrambi differenti prodotti dell'azienda. Le regole matematiche incorporate dichiarano che 55+66=121 e che 121 è più di 100. E, come già sappiamo, chi vende più di 100 prodotti diventa membro del club del Super Venditore. Il computer mette insieme queste regole logiche in una prova che Jane è un Super Venditore.
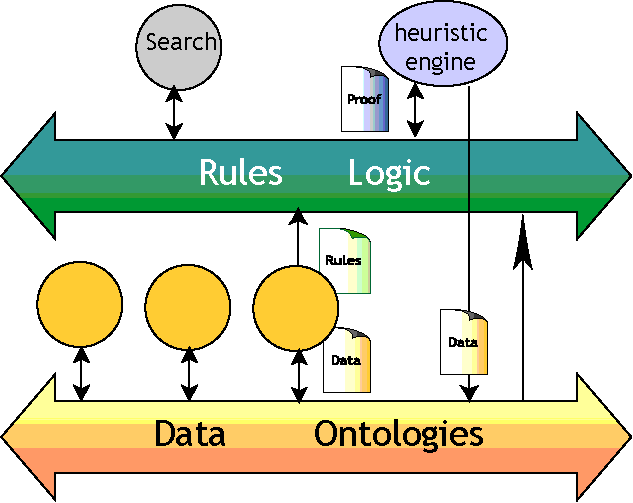
Mentre è molto difficile creare queste prove (può richiedere di seguire migliaia, forse milioni di link nel Web Semantico), è molto semplice controllarli. In questo modo, cominciamo a costruire un Web di processori di informazione. Alcuni di essi forniscono esclusivamente dati per l'uso di altri. Altri sono più intelligenti, e possono usare questi dati per costruire regole. I più intelligenti sono "motori euristici" che seguono tutte queste regole e dichiarazioni per disegnare conclusioni, e posizionano i loro risultati sul Web come prove, come pure dati vecchio stile.
Fiducia: Firme Digitali e Web di Fiducia
Ora starai sicuramente pensando che tutto ciò è grande, ma di poca utilità se ognuno può dire ogni cosa. Chi può dare fiducia a tutto questo sistema? Così, non mi permetti di entrare nel tuo sito? Ok, io dico che sono il Re del Mondo e che io ho il permesso. Poiché esiste la regola "ogni cosa può dire ogni cosa su ogni cosa", chi può fermarmi?
Ecco dove compare la Firma Digitale. Basata su lavori in matematica e crittografia, la firma digitale fornisce la prova che una certa persona ha scritto (o è d'accordo con) un documento o dichiarazione. Aha! Così io firmo digitalmente le mie dichiarazioni RDF. In questo modo puoi essere sicuro che le ho scritte (o almeno confermato la loro autenticità). Ora, tu dici al tuo programma a quali firme credere e a quali no. Ognuno può definire il proprio livello o fiducia (o paranoia) con il quale il computer può decidere quanto credere di quello che legge.
Ecco dove fa la sua comparsa il "Web di Fiducia" (Web of Trust). Dici al tuo computer che tu hai fiducia nel tuo migliore amico, Robert. Robert sembra essere piuttosto popolare sul Web e ha fiducia di molte persone. E naturalmente, tutte le persone di cui ha fiducia, hanno fiducia di un altro gruppo di persone. Ognuna di queste persone hanno fiducia in altre persone e così via. Queste relazioni di fiducia formano il "Web of Trust". E ognuna di queste relazioni ha associato un grado di fiducia (o di sfiducia).
Nota che la sfiducia può essere utile come la fiducia. Supponiamo che il tuo computer scopre un documento al quale nessuno ha dato esplicita fiducia, ma che nemmeno ha dato esplicita sfiducia. Molto facilmente il tuo computer darà fiducia a questo documento in più rispetto ad un documento che è stato esplicitamente sfiduciato.
Il computer prende tutti questi fattori in esame quando deve decidere il grado di fiducia di un pezzo di informazione. Esso può anche rendere questo processo trasparente o opaco secondo le tue preferenze, Per esempio, potresti essere felice con un semplice display "pollice su/pollice verso". Qualcun altro potrebbe invece volere una completa spiegazione, includendo anche una descrizione di alcuni o tutti i fattori che sono implicati nella decisione.
Tim Berners-Lee ha proposto un bottone "Oh, yeah?", che, quando viene cliccato, porterebbe il tuo computer a provare a fornire ragioni per dare fiducia ai dati. Ma, sia tu decida da solo o lasci decidere al tuo computer, l'informazione necessaria per realizzare decisioni approfondite sono disponibili attraverso il "Web of Trust".
Consclusione: la Grande Visione
Una delle migliori cose sul Web è che ci sono tante cose differenti per tante persone differenti. Il Web Semantico che sta per venire moltiplicherà questa versatilità per mille. Per alcuni, la caratteristica principale del Web Semantico sarà la facilità con la quale il PDA, il laptot, il desktop, il server e l'auto comunicheranno l'un l'altro. Per altri, essa sarà l'automazione di decisioni aziendali che precedentemente dovevano essere svolte in modo laborioso. Per altri ancora, essa sarà l'abilità di dare la fiducia a documenti sul Web e la facilità con la quale potremo trovare le risposte alle nostre domande - un processo che è attualmente realizzato con frustazione.
Qualunque sia la causa, già ognuno può trovare una ragione per supportare questa grande visione del Web Semantico. Sicuramente è una lunga strada da percorrere - e non esiste garanzia che la percorreremo - ma già abbiamo fatto un pò di progresso. Le possibilità sono senza fine, e anche se non le abbiamo ancora raggiunte tutte, il viaggio sarà certamente la sua propria ricompensa.
Ringraziamenti
Grazie a Sean B. Palmer per consigli dopo la prima bozza di quest'articolo. Egli ha pubblicato "The Semantic Web: An Introduction" che prende le mosse da questo lavoro. Jim Hendler e io abbiamo pubblicato un documento basato su questo lavoro dal titolo "Swartz, A. and Hendler, J. The Semantic Web: A Network of Content for the Digital City, Proceedings Second Annual Digital Cities Workshop, Kyoto, Japan, October, 2001." Charles F. Munat ha gentilmente corretto la mia scrittura; questa ultima versione contiene maggiori e nuove informazioni.
Ultima modifica di questo documento 2002-05-01 19:12:37